
Fine Tuning
- 1 min[toc]
Fine tuning
参考:
【大模型开发 】 一文搞懂Fine-tuning(大模型微调)_finetuning大模型-CSDN博客
江大白 深入浅出,Batch Size对神经网络训练的影响-CSDN博客
Fine tuning: 通过特定领域数据对预训练模型进行针对性优化, 以提升其在特定任务上的性能.
Fine-tuning的作用
- 定制化功能: 赋予大模型更加定制化的功能, 通过微调, 使LLM学习到特定领域的需求和特征(这里的适应更多的是指从表达方式上, 而不是从知识储备上)
- 领域知识学习: 通过引入特定领域的数据集, LLM可以学习到该领域的知识和语言模式, 这里的表达更侧重于知识储备
Fine-tuning的原理
微调流程
- 加载预训练的模型和权重
- 根据任务需求对模型的结构进行修改, 如增加输出层等(与Fine-tuning的类型有关)
- 选择合适的损失函数和优化器
- 使用选定的数据集进行微调训练
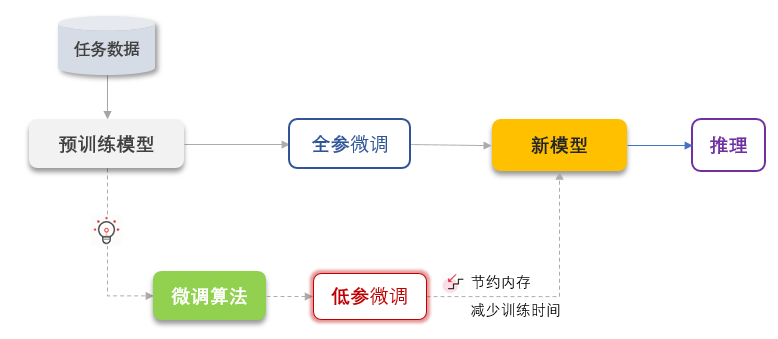
微调训练过程
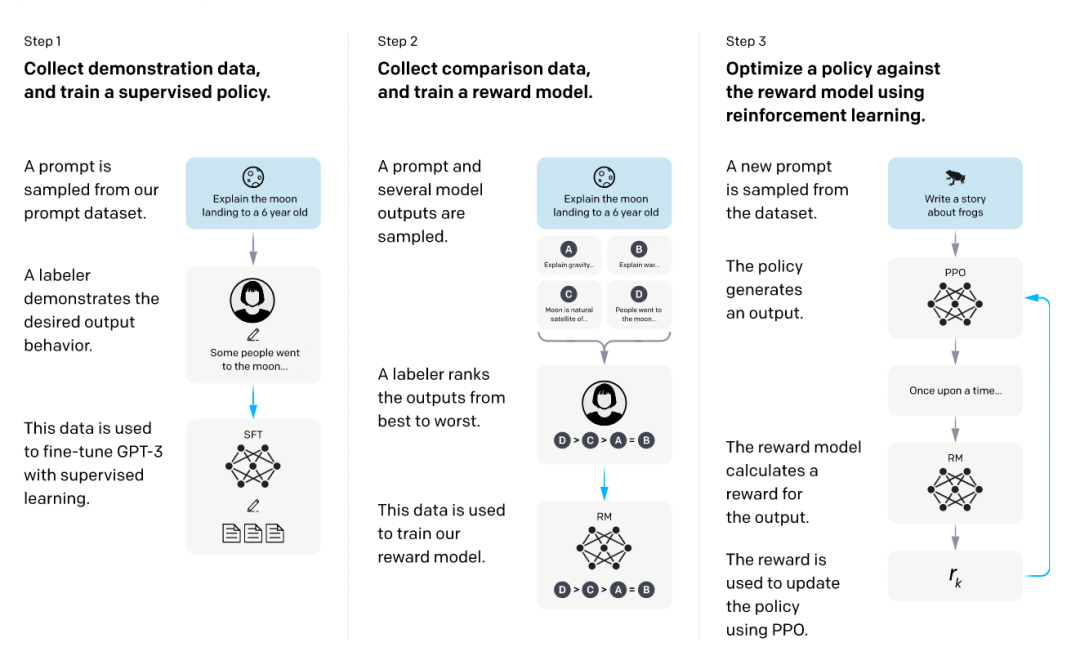
RLHF(Reinforcement Learning from Human Feedback): 一种利用人类反馈作为奖励信号来训练强化学习模型的方法, 旨在提升模型生成文本等内容的质量, 使其更符合人类偏好.
- 使用监督数据微调语言模型
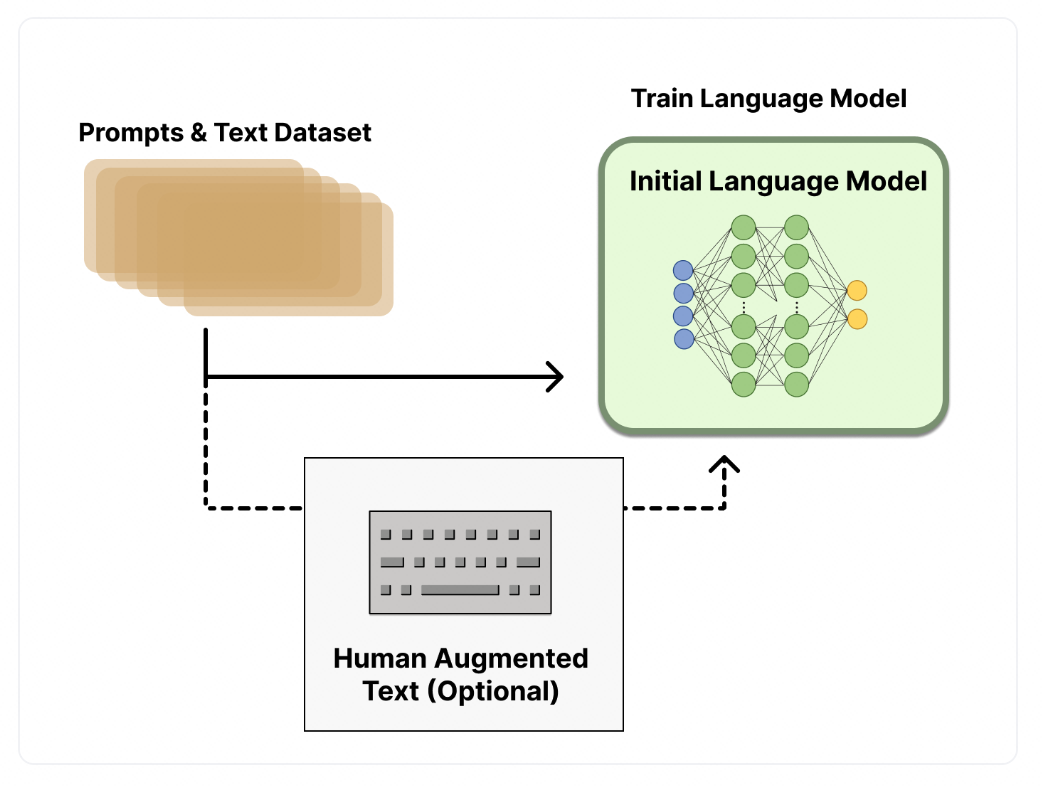
这一步可以使用标注过的数据来调整预训练模型的参数, 即使用问答对的格式化数据集进行训练
- 训练奖励模型

奖励模型用于评估文本序列(即LLM返回的回答的文本)的质量, 它接受一个文本作为输入, 并输出一个数值, 表示该文本符合人类偏好(或其他评判标准)的程度
训练数据通常由语言模型生成的多个文本序列组成(根据同一个问题生成的不同回答), 这些序列通过人工评估或使用其他更准确的模型(类似蒸馏中的teacher模型)进行打分
- 训练RL模型
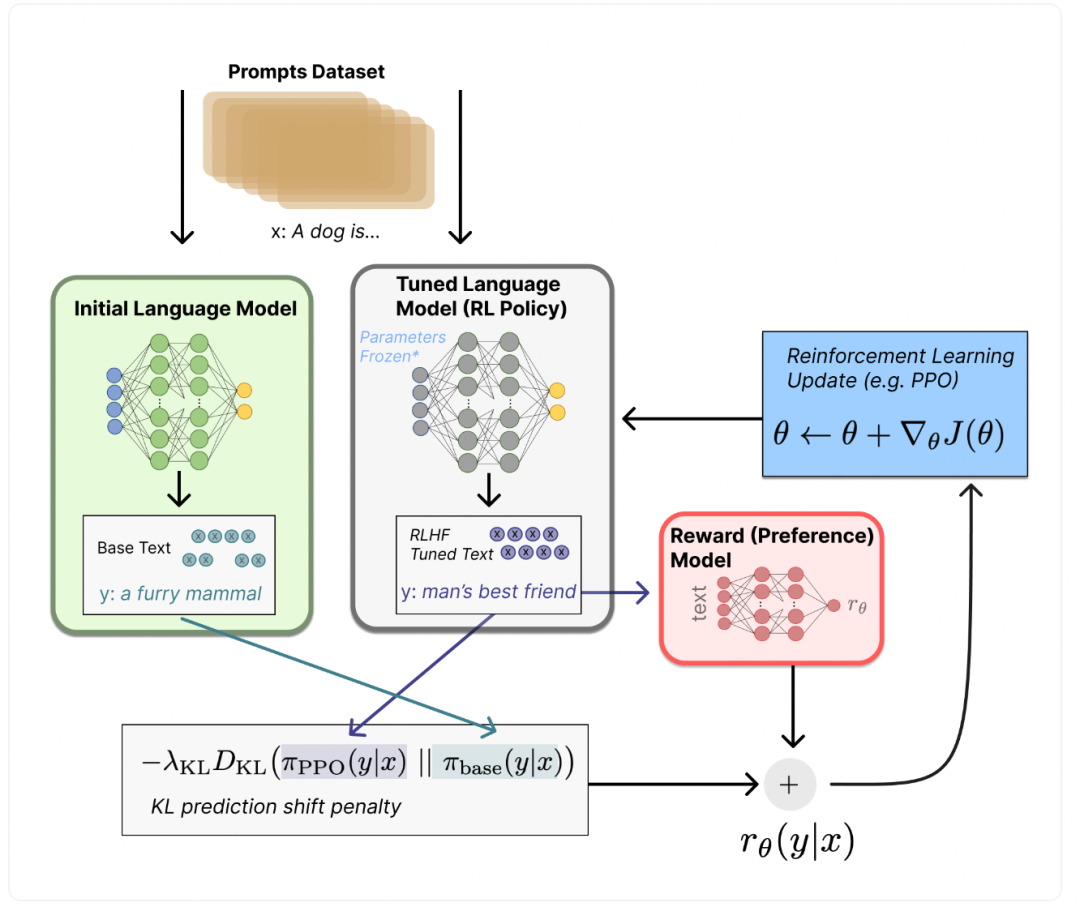
在强化学习框架中, 需要定义状态空间S, 动作空间A, 策略函数(即动作函数action)和价值函数(reward)
状态空间在LLM中为从文本开头到结尾的所有token, 其构成了状态空间
动作空间在LLM中就是其要预测的token的所有可能性, 即所有的token(其实也不多, 人类使用的词汇, 这些容纳人类所有知识和传承的词汇并不多, 在一套语言体系中, 超过99%的词大概也不过几万个)
策略函数在LLM中就是根据状态空间得出预测的下一个token的概率
价值函数则是根据RM模型(奖励模型)对当前产生的这一策略(动作)进行评价, 评估其价值
Fine-tuning的分类
全量微调 Full Fine-Tuning
调整预训练模型的所有参数(对LLM而言, 其参数量级为几十亿,上百亿), 以充分适应新任务.
它依赖大规模计算资源(没有显卡集群搞不了那种), 可能会产生灾难性遗忘, 但应用得到能有效利用预训练模型的通用特征(如对常识的认知等)
参数高效微调 Parameter-Efficient Fine-Tuning(PEFT)
旨在最小化微调参数数量和计算复杂度的情况下, 实现高效的迁移学习, 它仅更新模型中的部分参数, 可以显著降低训练时间和成本, 适用于计算和数据资源有限的情况, 包括Prefix Tuning, Prompt Tuning, Adapter Tuning等方法
因为太多, 所以单开一篇
| [Parameter-Efficient Fine-Tuning | Zhenshuai Yin (yin1245.github.io)](https://yin1245.github.io/Parameter-Efficient-Fine-Tuning/) |
Fine-tuning的实现方式
在选定相关数据集和预训练模型的基础上, 通过设置合适的超参数并对模型进行必要的调整, 使用特定任务的数据对模型进行训练以优化其性能.
训练流程
- 数据准备
- 选择数据集
- 对数据集进行预处理(清洗, 分词, 编码等)
- 选择基础模型
- 选择预训练好的基座模型, 如GPT-3, ChatGLM等
- 设置微调的超参数
- 开始训练
微调数据集形式(适用于上面提到的使用监督数据微调LLM)

intruduction字段通常用于描述任务类型或给出的指令
input字段包含的是user提出的问题
output字段是人类认为的正确回答
注意事项
在微调过程中, 超参数(如learning rate, batch size, epoch)的调整非常重要, 需要根据特定任务和数据集进行调整, 一般而言, learning rate大了, 训练速度快, 但不容易收敛, (可能适合一个粗略的对齐?一般量级为10^-4^或10^-5^), batch size为每次的批处理大小, 大的batch size需要更大的GPU显存, 训练速度会更快, 但训练效果可能性能更差. 需要注意的是, batch size和learning rate要同步调整, 小的batch在小learning rate下表现最好, 而大batch size在大的learning rate下表现最好(如果大批量训练在相同学习率下优于小批量训练, 这可能表明学习率大于小批量训练的最佳值, 这时可以选择调小learning rate), 而epoch可以设置一个适当大的值, 然后直到收敛(或者波动小于某个设定值)或者到达设定的epoch.