
COSTAR框架及其他构建提示词策略
- 1 min| 参考: [COSTAR结构化表达框架,助我夺冠新加坡首届 GPT-4 提示工程大赛 | 申导 (jackyshen.com)](https://www.jackyshen.com/2024/05/07/How-I-Won-Singapore’s-GPT-4-Prompt-Engineering-Competition/) |
COSTAR框架
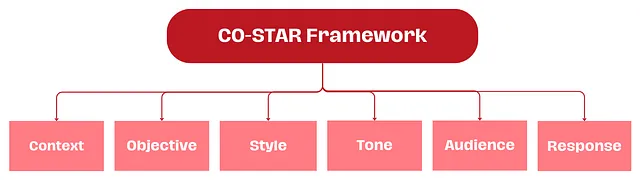
CO-STAR 框架,由新加坡政府科技局数据科学与 AI 团队创立,是一个实用的提示构建工具。
- (C) 上下文:为任务提供背景信息 通过为大语言模型(LLM)提供详细的背景信息,可以帮助它精确理解讨论的具体场景,确保提供的反馈具有相关性。
- (O) 目标:明确你要求大语言模型完成的任务 清晰地界定任务目标,可以使大语言模型更专注地调整其回应,以实现这一具体目标。
- (S) 风格:明确你期望的写作风格 你可以指定一个特定的著名人物或某个行业专家的写作风格,如商业分析师或 CEO。这将指导大语言模型以一种符合你需求的方式和词汇选择进行回应。
- (T) 语气:设置回应的情感调 设定适当的语气,确保大语言模型的回应能够与预期的情感或情绪背景相协调。可能的语气包括正式、幽默、富有同情心等。
- (A) 受众:识别目标受众 针对特定受众定制大语言模型的回应,无论是领域内的专家、初学者还是儿童,都能确保内容在特定上下文中适当且容易理解。
- (R) 响应:规定输出的格式 确定输出格式是为了确保大语言模型按照你的具体需求进行输出,便于执行下游任务。常见的格式包括列表、JSON 格式的数据、专业报告等。对于大部分需要程序化处理大语言模型输出的应用来说,JSON 格式是理想的选择。
CO-STAR示例
# CONTEXT(上下文) # 我想推广公司的新产品。我的公司名为 Alpha,新产品名为 Beta,是一款新型超快速吹风机。
# OBJECTIVE(目标) # 帮我创建一条 Facebook 帖子,目的是吸引人们点击产品链接进行购买。
# STYLE(风格) # 参照 Dyson 等成功公司的宣传风格,它们在推广类似产品时的文案风格。
# TONE(语调) # 说服性
# AUDIENCE(受众) # 我们公司在 Facebook 上的主要受众是老年人。请针对这一群体在选择护发产品时的典型关注点来定制帖子。
# RESPONSE(响应) # 保持 Facebook 帖子简洁而深具影响力。
使用分隔符进行语义分割
分隔符示例:
###
===
»>
示例
请在 «» 中对每段对话的情绪进行分类,标为‘正面’或‘负面’。仅提供情绪分类结果,不需任何引言。
对话示例
«Agent: 早安,我今天怎么为您服务?Customer: 很喜欢你们的产品。它超出了我的预期!»
输出示例
负面
正面
将XML标签作为分隔符
使用 XML 标签作为分隔符是一种方法。XML 标签是被尖括号包围的,包括开启标签和结束标签。例如,< tag >和< /tag>。这种方法非常有效,因为大语言模型已经接受了大量包含 XML 格式的网页内容的训练,因此能够理解其结构。
输出示例
负面
正面
利用LLM中给出的系统提示创建机制
在ChatGPT中, 可以通过设置系统提示, 系统消息和自定义指令来进行Prompt-Tuning, 这三者的本质相同, 下面是具体含义:
- “系统提示”和“系统消息”是通过 Chat Completions API 编程方式交互时使用的术语。
- 而“自定义指令”则是在通过 https://chat.openai.com/ 的用户界面与 ChatGPT 交互时使用的术语。
什么是系统提示
系统提示是您向大语言模型提供的关于其应如何响应的额外指示。这被视为一种额外的提示,因为它超出了您对大语言模型的常规用户提示。
在对话中,每当您提出一个新的提示时,系统提示就像是一个过滤器,大语言模型会在回应您的新提示之前自动应用这一过滤器。这意味着在对话中每次大语言模型给出回应时,都会考虑到这些系统提示。(也就是说, 将系统提示拼接到你的输入之前)
系统提示一般包括以下几个部分:
- 任务定义:确保大语言模型(LLM)在整个对话中清楚自己的任务。
- 输出格式:指导 LLM 如何格式化其回答。
- 操作边界:明确 LLM 不应采取的行为。这些边界是 LLM 治理中新兴的一个方面,旨在界定 LLM 的操作范围。
例如,系统提示可能是这样的:
您需要用这段文本来回答问题:[插入文本]。
请按照
{"问题": "答案"}的格式来回答。如果文本信息不足以回答问题,请以”NA”作答。您只能解答与[指定范围]相关的问题。请避免回答任何与年龄、性别及宗教等人口统计信息相关的问题。
