
电力大模型
- 1 min注: 于2023年8月至2024年1月进行的本项目, 项目获得了全球大学生人工智能算法精英大赛的全国三等奖
参考: LLaMA-Factory参数的解答(命令,单卡,预训练)_llama factory多显卡训练-CSDN博客
增量预训练,在所属领域数据上继续预训练,主要问题是灾难性遗忘_什么是增量预训练-CSDN博客
涉及的知识点:
LoRA的特点
增量预训练
fine-tuning
工程创新: 因赛方提供了单选, 多选和问答三种类型, 在增量预训练之后分别对其进行相应题型的fine-tuning
RAG之Langchain实现
RAG之向量数据库的选择, Embedding模型的选择和说明, 文本分割方式的选择与讲解
教训: 适当的调整模型温度可能会有更好的结果
Background
赛题分析:
赛题为使用LLM对电力领域知识的问答, 题型包括单选, 多选和问答题, 模型需以给定的基座模型(ChatGLM2-6B)为基础, 进行操作, 尽可能提高其准确率.
实现方案
增量预训练(也是LoRA)
首先将赛方提供的数据集(几本专业书籍)结合在网上找到的其他专业方向的书籍, 将其整合到一起, 进行增量预训练, 以期增加LLM的专业知识储备.
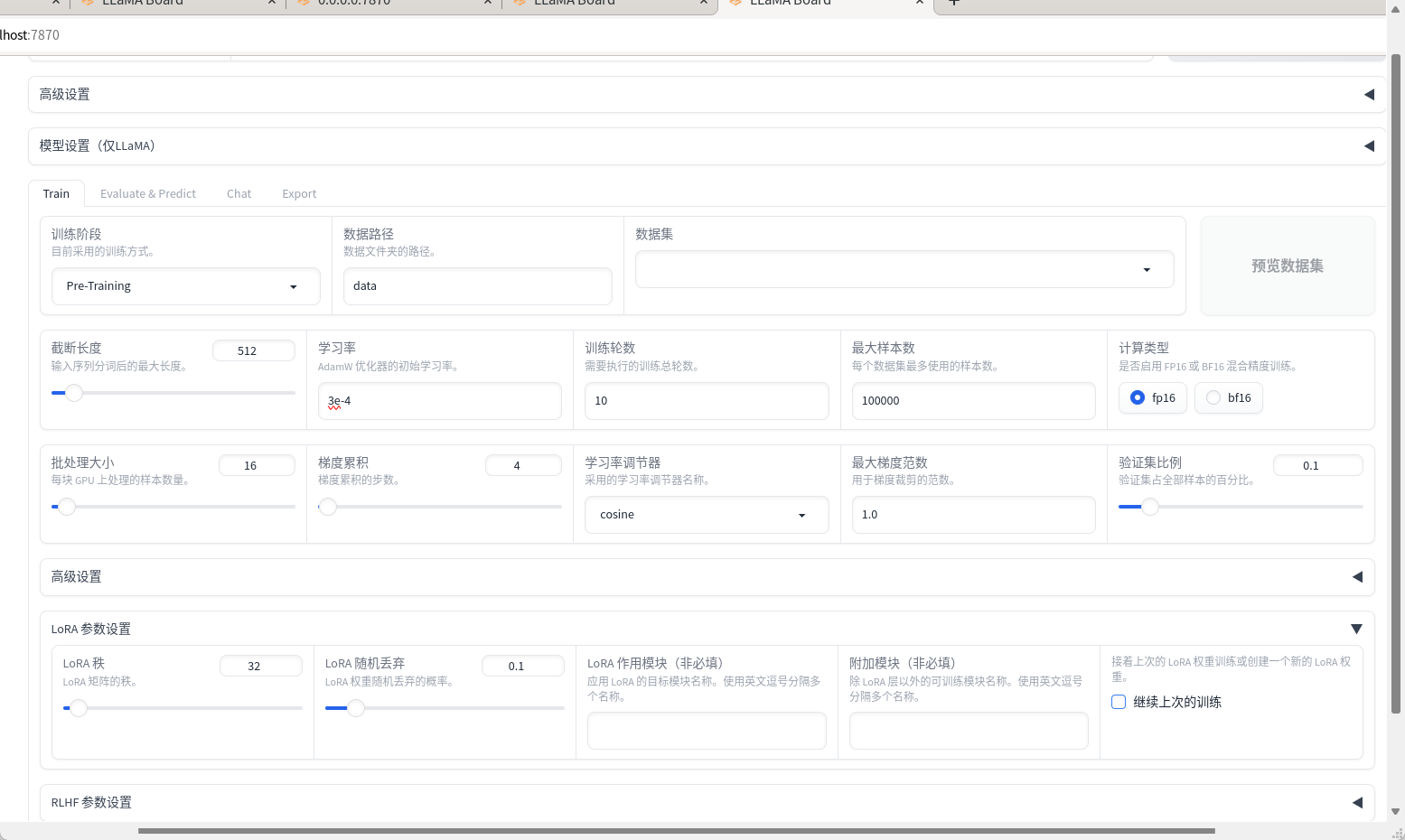
LoRA fine-tuning
在网上查找相关领域的单选, 多选和问答题, 并且使用ChatGPT4根据赛方提供的数据集生成问答对, 将其整合到一起进行fine-tuning, 在改变模型输出格式(只输出选项)的同时, 进一步稳固其专业知识储备.
RAG
为缓解大模型的幻觉问题和其在专业知识领域回答仍然不稳定的问题, 我们选择使用 RAG. 以Langchain为基础, 修改其返回函数, 将其与主文件以request请求的方式结合起来, 将topk个数据拼接到输入的上下文.
向量库: milvus
Embedding模型: gte-large-zh
文本分割方式: Langchain默认(ChineseRecursiveTextSplitter)
原理整理
LoRA的特点
全称是“Low-Rank Adaptation”。可以理解为一种轻量级的模型调整方式。它主要是在模型的某些核心部分插入小的、低秩的矩阵,通过调整这些小矩阵来实现对整个模型的微调。这种方法不需要对原始模型的大部分参数进行重训练,从而可以在不牺牲太多性能的情况下,快速适应新的任务或数据, 可以达到近乎全量的效果.
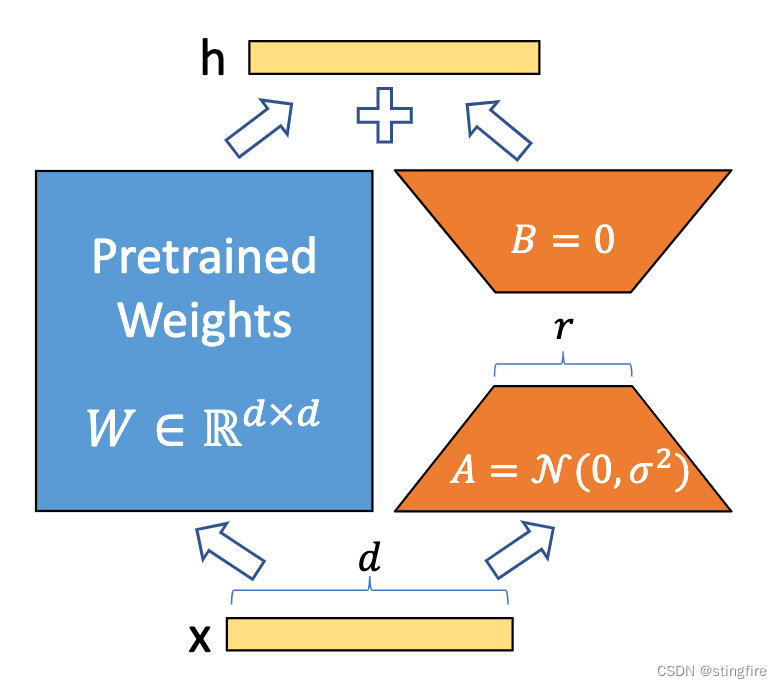
LoRA target
指定LoRA调整的目标层,这里是q_proj和v_proj。 在使用LoRA(Low-Rank Adaptation,低秩适应)技术进行模型微调时,我们通常会选择模型中的特定层(或部分)进行调整。这些层被称为“目标层”。 具体来说: 1.q_proj:通常指的是在自注意力机制中,用于生成查询(Query)向量的投影层。 2.v_proj:指的是在自注意力机制中,用于生成值(Value)向量的投影层。 自注意力机制是Transformer模型的核心组成部分。在这种机制中,输入数据会被转换成三种类型的向量:查询(Query)、键(Key)、值(Value)。这些转换通常通过线性投影实现,即通过乘以一个权重矩阵。 在使用LoRA进行微调时,我们不直接修改这些投影层的权重矩阵,而是在这些层插入低秩矩阵。通过优化这些低秩矩阵,我们可以在不显著改变原始模型结构的情况下,有效地调整模型的行为,使其更好地适应新的任务或数据。
增量预训练(领域自适应预训练)
为了给模型注入领域知识, 就需要用领域内的语料进行继续预训练
一般而言, 这一步的数据集来自: 网上已有, 企业私有, ChatGPT扩充
这一步的数据集相对比较简单, 是一些垂直领域文章的内容, 如书籍, 博客等
增量预训练同样可以以LoRA的形式, 这样可以大大节省计算成本
增量预训练后可能发生灾难性遗忘
避免灾难性遗忘要从以下几方面出发:
1.领域相关性(增量数据与所选基座模型的原始训练数据尽量有一定相关性)(至少语言相通吧)
2.新数据分布与原始数据尽量相似: 领域数据和通用数据的比率, 结合具体数据: 10%,15%,20%都有
3.降低学习率: 需要多跑几个epoch
4.进行warm up
fine-tuning
通过SFT激发大模型理解领域内的各种问题并进行回答的能力
RAG之Langchain实现
通过修改Langchain-Chatchat2/server/chat/knowledge_base_chat.py, 实现返回topk个检索结果的功能.
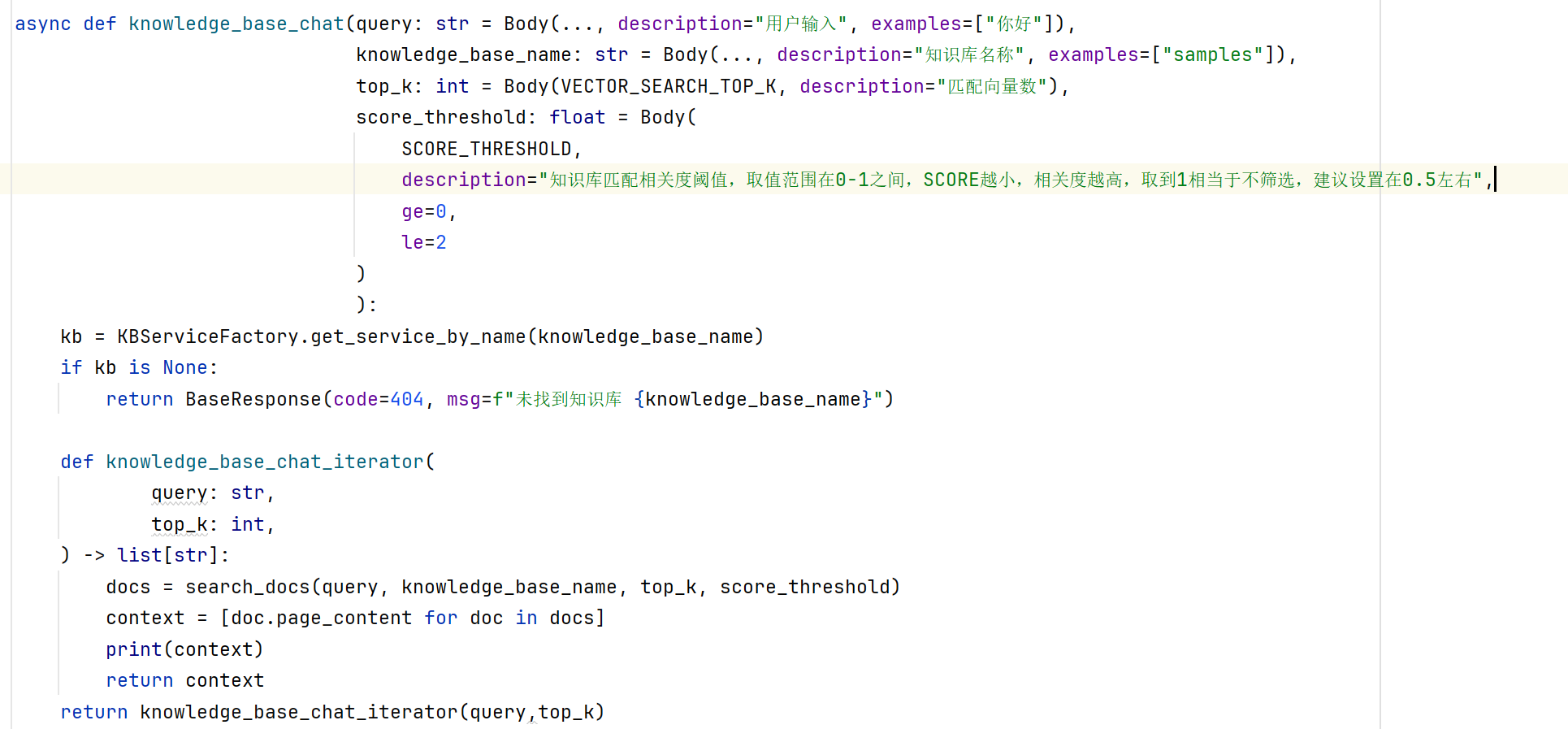
向量数据库的选择
开源向量数据库比较:Chroma, Milvus, Faiss,Weaviate-腾讯云开发者社区-腾讯云 (tencent.com)
向量数据库是一种将数据存储为高维向量的数据库,高维向量是特征或属性的数学表示。每个向量都有一定数量的维度,根据数据的复杂性和粒度,可以从数十到数千不等。
向量通常是通过对原始数据(如文本、图像、音频、视频等)应用某种转换或嵌入函数来生成的。嵌入函数可以基于各种方法,如机器学习模型、词嵌入和特征提取算法。
向量数据库的主要优点是,它允许基于数据的向量距离或相似性进行快速和准确的相似性搜索和检索。
这意味着不用使用基于精确匹配或预定义标准查询数据库的传统方法,而是可以使用向量数据库根据语义或上下文含义查找最相似或最相关的数据。
Chroma
向量数据库 Chroma 是一种专门设计用来高效管理和查询向量数据的数据库系统。Chroma 通过其高效的数据结构和算法优化,能够快速处理和检索大量的向量数据。
以下是 Chroma 向量数据库的一些主要特点:
- 高效的向量索引:Chroma 使用高效的索引结构,如倒排索引、KD-树或基于图的索引,以加快向量搜索速度。
- 支持多种相似度度量:它支持多种向量相似度度量标准,包括欧氏距离、余弦相似度等,使其可以广泛应用于不同的应用场景。
- 可扩展性和弹性:Chroma 能够支持水平扩展,适应大规模数据集的需要。同时,它也能有效处理数据的动态变化,适应快速发展的存储需求。
- 易于集成和使用:Chroma 设计有易于使用的API接口,支持多种编程语言接入,便于开发者在不同的系统和应用中集成使用。
- 实时性能优化:Chroma 优化了查询处理过程,支持实时的数据查询和更新,满足实时分析和决策的需求。
Milvus
Milvus 提供了高效的向量检索能力,特别适合用于机器学习和人工智能领域,如推荐系统、图像检索和自然语言处理等。Milvus 支持海量数据的快速检索,以及灵活的数据更新和扩展功能。
以下是 Milvus 的一些关键特点:
- 高效的向量索引:Milvus 支持多种索引类型,如倒排索引、HNSW、IVF 等,用户可以根据具体需求选择最合适的索引策略来优化检索性能。
- 多种相似度度量:它支持多种相似度计算方法,包括欧氏距离、余弦相似度等,以满足不同场景下的需求。
- 可扩展性:Milvus 能够在不同的硬件和平台上运行,支持在云环境中部署。其架构支持水平和垂直扩展,适应从小规模到大规模的应用需求。
- 强大的API支持:Milvus 提供了丰富的API,包括Python、Java、Go等多种语言的SDK,便于开发者集成和使用。
- 云原生支持:Milvus 支持在Kubernetes环境中部署,使得其能够利用云原生技术的优势,如容器化、微服务架构和自动化管理。
FAISS
Faiss 是由 Facebook AI Research(FAIR)开发的一个高效的库。Faiss 特别适合处理大量高维数据的相似度搜索任务,常用于机器学习和人工智能领域中的应用,如图像检索、视频推荐和自然语言处理等。
以下是 Faiss 的一些关键特性:
- 高效的索引结构:Faiss 提供多种索引结构和搜索算法,包括扁平(flat)索引、倒排文件(IVF)索引和基于量化的索引(如 PQ 和 OPQ)。这些索引能够在维护较高查询精度的同时,显著提高搜索速度。
- 支持批量查询:Faiss 设计了优化的批处理查询,能够同时处理多个查询,这样可以充分利用现代多核CPU的计算资源,极大提高处理速度。
- 灵活的距离计算:它支持多种距离计算方法,包括L2(欧氏距离)和内积,用户可以根据具体需求选择适合的度量方式。
- GPU加速:Faiss 还提供了GPU版本,可以利用GPU强大的并行处理能力来进一步加速向量搜索和聚类计算。
- 易于集成和使用:Faiss 可以与 Python 紧密集成,通过提供的 Python 接口,用户可以方便地在 Python 环境中使用 Faiss 进行数据处理和分析。
Weaviate
Weaviate 是一个开源的向量搜索引擎,它采用了最新的机器学习模型来优化向量搜索和存储。Weaviate 使用图数据结构来组织数据,支持高效的向量索引和近似最近邻(ANN)搜索。
以下是 Weaviate 的一些关键特性:
- 基于图的数据模型:Weaviate 使用图数据结构来存储和管理数据,每个数据点都作为图中的一个节点,这些节点可以通过边相互连接,以表示复杂的数据关系。
- 机器学习集成:Weaviate 直接集成了机器学习模型,如Transformer模型,用于自动将文本和其他数据类型转换成高维向量。这种集成简化了AI驱动应用的开发流程。
- 模块化和可扩展:Weaviate 的架构支持模块化,用户可以根据需要添加不同的模块来扩展功能,如自定义向量化模块或特定的数据连接器。
- 实时索引与查询:Weaviate 设计了实时数据索引和查询的能力,支持在大规模数据集上进行高效的向量搜索。
- 丰富的API和客户端支持:Weaviate 提供了RESTful API、GraphQL接口,以及多种客户端库(如Python、JavaScript),便于开发者使用和集成。
- 云原生和高可用性:Weaviate 是为云环境优化的,支持在Kubernetes上部署,确保了高可用性和弹性。
对比
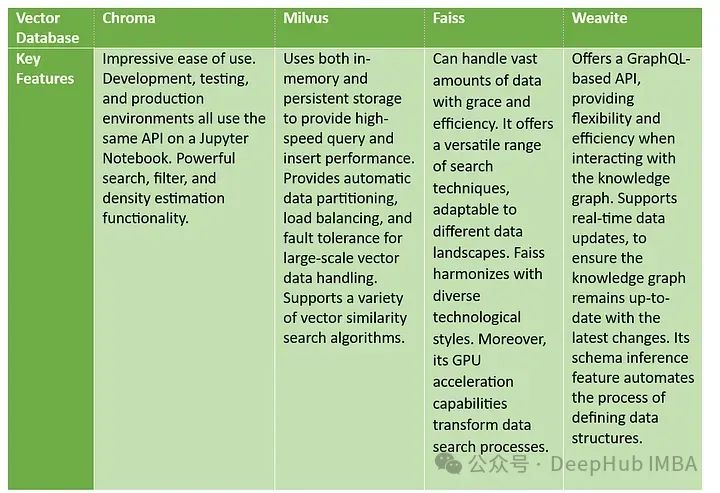
- 易用性: Chroma 强调在 Jupyter Notebook 上的易用性,而 Weaviate 则强调其 GraphQL API 的灵活性和效率。
- 存储与性能: Milvus 在存储和查询性能方面提供了内存与持久存储的结合,相比之下,Faiss 强调 GPU 加速能力在搜索过程中的作用。
- 数据处理与更新: Milvus 提供自动数据分区和容错,Weaviate 支持实时数据更新,确保数据的时效性。
- 搜索技术: Chroma 和 Milvus 都提到了它们对搜索算法的支持,而 Faiss 则提供了适应不同技术风格的搜索技术,Weaviate 使用 GraphQL 提高了数据结构定义的效率。
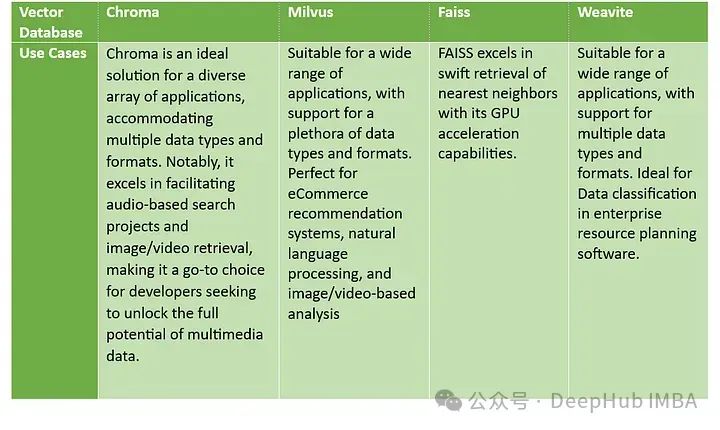
Chroma擅长处理多媒体内容,Milvus 提供通用的数据处理能力且特别适合于推荐系统和语言/视觉分析,Faiss 强调其 GPU 加速在搜索上的优势,而 Weaviate 则以其在企业级数据管理中的应用为特色。
总结
Chroma在易用性上占优,特别适合在Jupyter Notebook上进行开发、测试和生产,是处理多媒体数据,尤其是音频和视频搜索的理想选择。
Milvus强调在存储效率和数据查询性能上的平衡,支持内存和持久存储,适用于各种数据类型和格式。它在电子商务、自然语言处理以及图像和视频分析等多个方面有广泛应用,特别是在数据分区、负载均衡和容错方面提供了强大的支持。
Faiss可以进行GPU加速的高速检索,特别擅长处理庞大数据集的快速最近邻搜索,适用于不同技术需求和数据环境,能够与多种技术风格相协调。
Weaviate则提供了GraphQL-based API,强调与知识图的灵活高效交互。支持实时数据更新,确保数据的时效性,以及通过模式推断功能,自动化了数据结构定义的过程,适合于需要数据分类和企业资源规划的场合。
它们都能提供高效的搜索能力和处理大规模数据集的能力,但在细节实现和特定功能上各有侧重,这需要根据实际业务需求来决定最合适的选择。选择使用哪个库将取决于数据的类型、处理需求和预期的使用场景。
Embedding模型的选择
用通俗易懂的方式讲解:选择最佳的 Embedding 和重排序模型,提升大模型 RAG 效果特别明显!_知识库rag任务中的检索之后有哪些重排序模型-CSDN博客
使用Retrieval Evaluation评估Embedding模型的优劣
理解Retrieval Evaluation的评估指标
为了衡量我们的检索系统的有效性,我们选择被广泛接受的两个指标:Hit Rate和 Mean Reciprocal Rank (MRR)。让我们深入研究这些指标,以了解它们的重要性以及它们是如何运作的。
命中率(Hit Rate):
命中率计算在前k个检索到的文档中找到正确答案的查询的百分比。简单地说,这是关于我们的系统在前几次猜测中正确的频率。
平均倒数排名(MRR):
对于每个查询,MRR通过查看排名最高的相关文档的排名来评估系统的准确性。具体来说,它是所有查询中这些排名的倒数的平均值。因此,如果第一个相关文档是最高结果,则倒数为1;如果是第二个,则倒数为1/2,依此类推。
具体过程参考原blog
11、结论 在这篇博客文章中,我们展示了如何使用各种embedding和重排序来评估和增强检索器的性能。以下是我们的最终结论。
Embeddings:OpenAI和JinaAI-Base embedding,尤其是与CohereRerank**/bge-reranker-large reranker配对时,为命中率和MRR设定了黄金标准。
Rerankers:重新排序的影响,特别是CohereRerank**/bge-reranker-large 重新排序,怎么强调都不为过。它们在改善许多embedding的MRR方面发挥着关键作用,表明了它们在改善搜索结果方面的重要性。
Foundation is Key:为初始搜索选择正确的embedding至关重要;如果基本搜索结果不好,即使是最好的重新排序也无济于事。
Working Together:为了让检索器发挥出最大的作用,找到embedding和重新排序的正确组合是很重要的。这项研究表明,仔细测试并找到最佳配对是多么重要。
文本分割方式
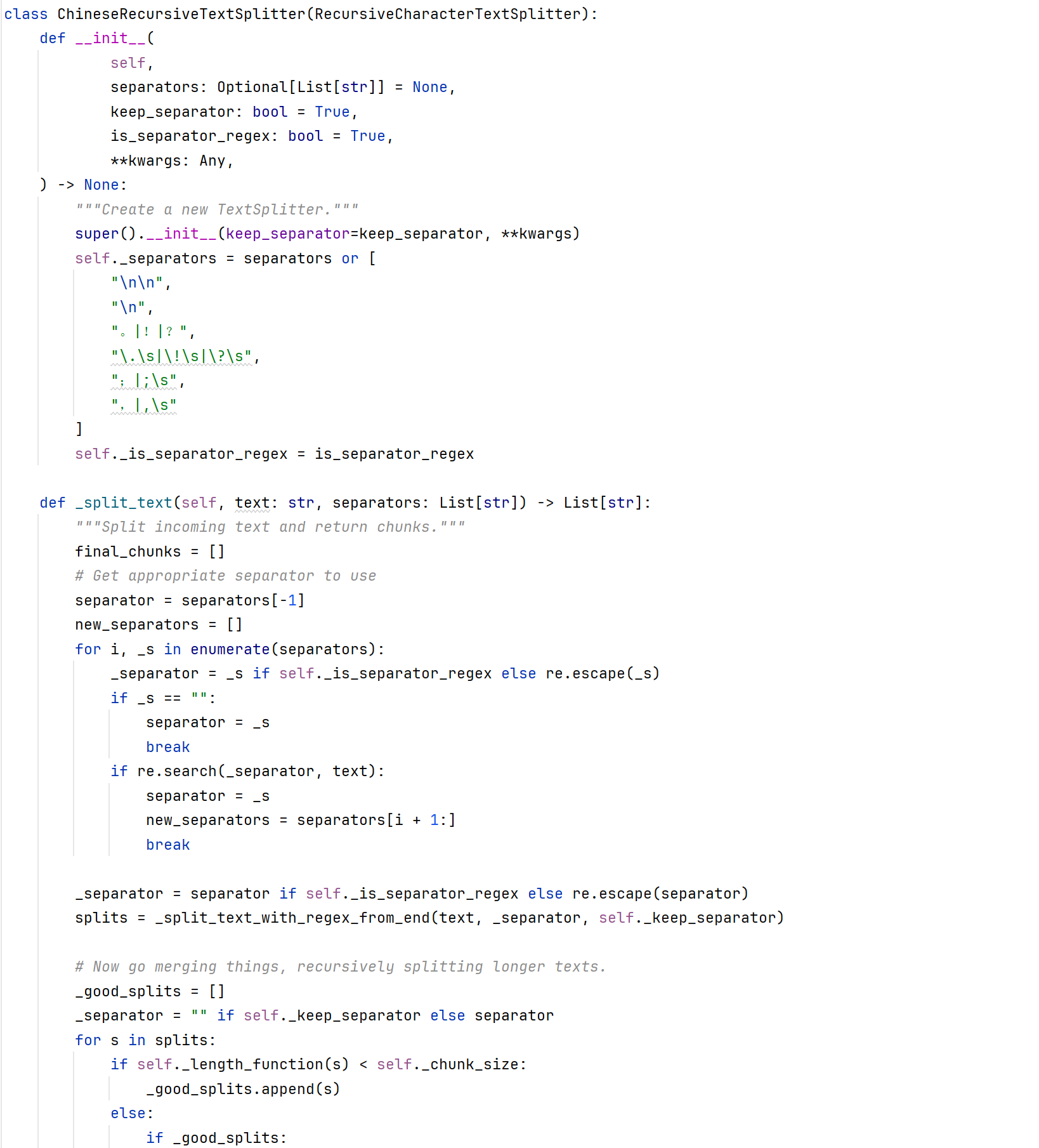
具体方式为根据符号进行分割(自认为是比较合适的一种方式了)